
GeoGen3DHuman : un projet de recherche international pour des avatars hyperréalistes
Avatars personnalisés capables d’interagir avec nous, personnages virtuels pour des applications de soins ou encore actrices et acteurs de cinéma virtuels feront partie de notre quotidien dans un avenir proche. Mais pour y arriver, ces avatars devront prendre en compte les informations tridimensionnelles du visage pour augmenter le réalisme et permettre des variations naturelles de l'expression faciale. Le projet de recherche international (IRP) GeoGen3DHuman cherche à répondre à cette problématique : comment, à partir d’une simple photographie, générer un avatar capable de changer d’expression faciale de manière réaliste ?
Au cours des dernières années, l'intelligence artificielle (IA) a permis plusieurs avancées dans le domaine de la génération d’avatars en 3D. Des modèles génératifs capables de synthétiser des visages humains en 3D ou de reconstruire le visage d’un sujet à partir d’une vue monoculaire de manière très crédible et convaincante ont vu le jour. Cependant, il existe encore plusieurs écarts entre les modèles synthétiques du visage 3D et les visage 3D réels, en particulier dans la génération d'avatars entièrement animés présentant des expressions faciales naturelles et des transitions fluides entre différentes expressions sur de longues périodes. À cela s’ajoute un autre défi technique pour les scientifiques : la synchronisation parfaite entre un signal audio et les mouvements des lèvres, la pose et l'expression du visage des têtes parlantes générées.
C’est ici qu’intervient l’IRP GeoGen3DHuman. Issu d’une collaboration entre le Centre de recherche en informatique, signal et automatique de Lille (CRIStAL - CNRS/Centrale Lille/Université de Lille), l’IMT Nord Europe et le Media Integration and Communication Center (MICC) de l’Université de Florence, cet IRP réunit des spécialistes de l’analyse de visages en 3D.
L’objectif de recherche des partenaires est de mettre en œuvre des modèles génératifs pour des visages et corps humains en 3D. Après une phase d'entraînement, ces modèles produisent de nouveaux visages ou corps 3D, différents des données d'entraînement, mais qui appartiennent toujours à la même distribution de données. Alors que de tels modèles génératifs ont démontré leur efficacité dans plusieurs domaines de l'imagerie (par exemple la génération de visage d’un réalisme impressionnant), peu de travaux ont exploré les modèles génératifs travaillant dans des domaines non euclidiens (c'est-à-dire dans un espace courbé), tels que ceux qui proviennent des réseaux sociaux, des graphiques de molécules, ou encore les maillages 3D et les nuages de points 3D en infographie.
Sur la base de ces prémisses, les scientifiques de l’IRP GeoGen3DHuman ont d'abord proposé une nouvelle solution pour générer des expressions faciales 3D dynamiques à partir d'un visage 3D neutre et d'une étiquette d'expression. Cela permet, par exemple, de partir d’un modèle de visage 3D générique en expression neutre et de l'animer avec une étiquette d'expression donnée (par exemple, heureuse, triste, en colère, etc.).
Le résultat est une séquence temporelle animée de modèles de visage 3D avec une expression variant de la neutralité à un pic dans l’expression donnée. Le modèle est indépendant de l'identité, c’est-à-dire qu’il permet de générer des expressions diverses pour différentes personnes. Cela le rend applicable dans des scénarios où des expressions faciales personnalisées sont requises.
Le modèle proposé par les scientifiques de l’IRP comprend deux réseaux neuronaux profonds. Le premier, appelé Motion3DGAN, prend en compte la dynamique de l'expression. Il génère un mouvement temporellement cohérent des repères 3D du visage qui correspond à une transition spécifiée entre deux expressions à partir d'un signal de bruit. La séquence finale de maillages est ensuite générée par le décodeur de maillage Sparse2Dense (S2D-Dec) qui cartographie les déplacements des points de repère vers un déplacement dense par sommet d'une topologie de maillage connue.
Ces résultats ouvrent de nouvelles applications telles que les transitions dynamiques entre les expressions et le transfert d'expressions faciales ou de la parole entre les identités.
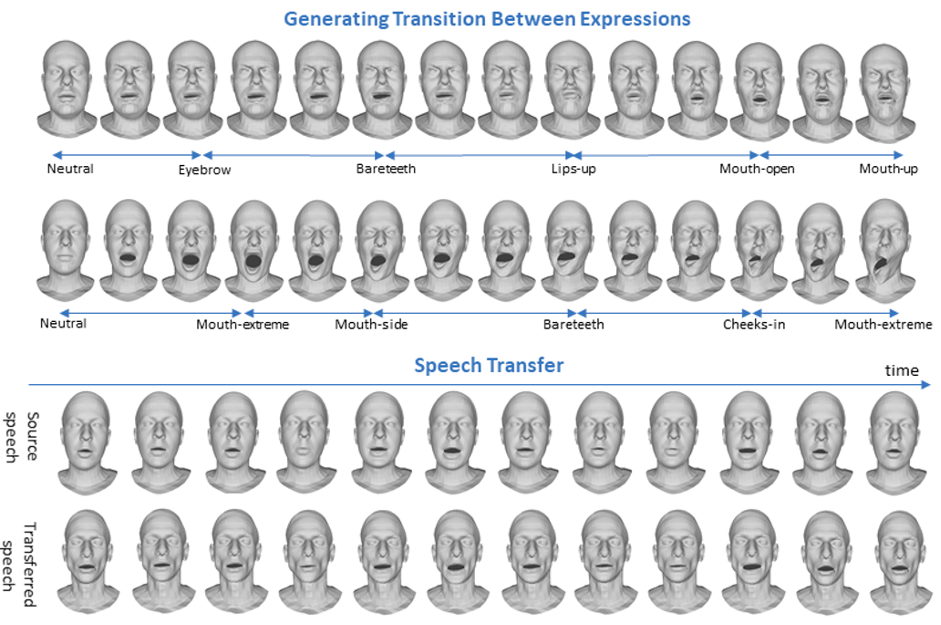
© Otberdout and al. IEEE Transactions on Affective Computing, 2023.
Ce modèle a ensuite été étendu pour générer des séquences de visages 3D avec des transitions fluides entre plusieurs expressions. Ce faisant, un résultat supplémentaire a émergé du projet : un corpus de données a été créé pour lequel un grand nombre d'expressions et de séquences de transition d'expressions sont fournies pour des modèles de visages réels et synthétiques.
Cependant, les données acquises par ces modèles sont souvent incohérentes, ce qui se traduit par des maillages ou des nuages de points non alignés. Les scientifiques de l’IRP vont donc poursuivre leurs travaux avec notamment la conception d’algorithmes d’apprentissage génératif avec des données incohérentes. En plus de perfectionner les modèles déjà existants, ils exploreront la génération multimodale de visages en 3D (audio et texte), qui pourra, dans un futur plus ou moins proche, être étendue à la génération de corps humains en 3D.
Vous pouvez suivre l'évolution du projet sur le site internet de l’IRP GeoGen3DHuman et sur son compte twitter.
Publications
- Naima Otberdout, Claudio Ferrari, Mohamed Daoudi, Stefano Berretti, Alberto Del Bimbo. Sparse to Dense Dynamic 3D Facial Expression Generation. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages.20353-20362, 2022.
- Naima Otberdout, Claudio Ferrari, Mohamed Daoudi, Stefano Berretti, Alberto Del Bimbo. Generating Complex 4D Expression Transitions by Learning Face Landmark Trajectories. IEEE Transactions on Affective Computing, To appear, 2023.
- Filippo Principi, Stefano Berretti, Claudio Ferrari, Naima Otberdout, Mohamed Daoudi, Alberto Del Bimbo. The Florence 4D Facial Expression Dataset. IEEE Conf. on Face and Gesture Recognition (FG), page 1-6, 2023.